Docs
Author:
Fluent Commerce
Changed on:
22 Aug 2024
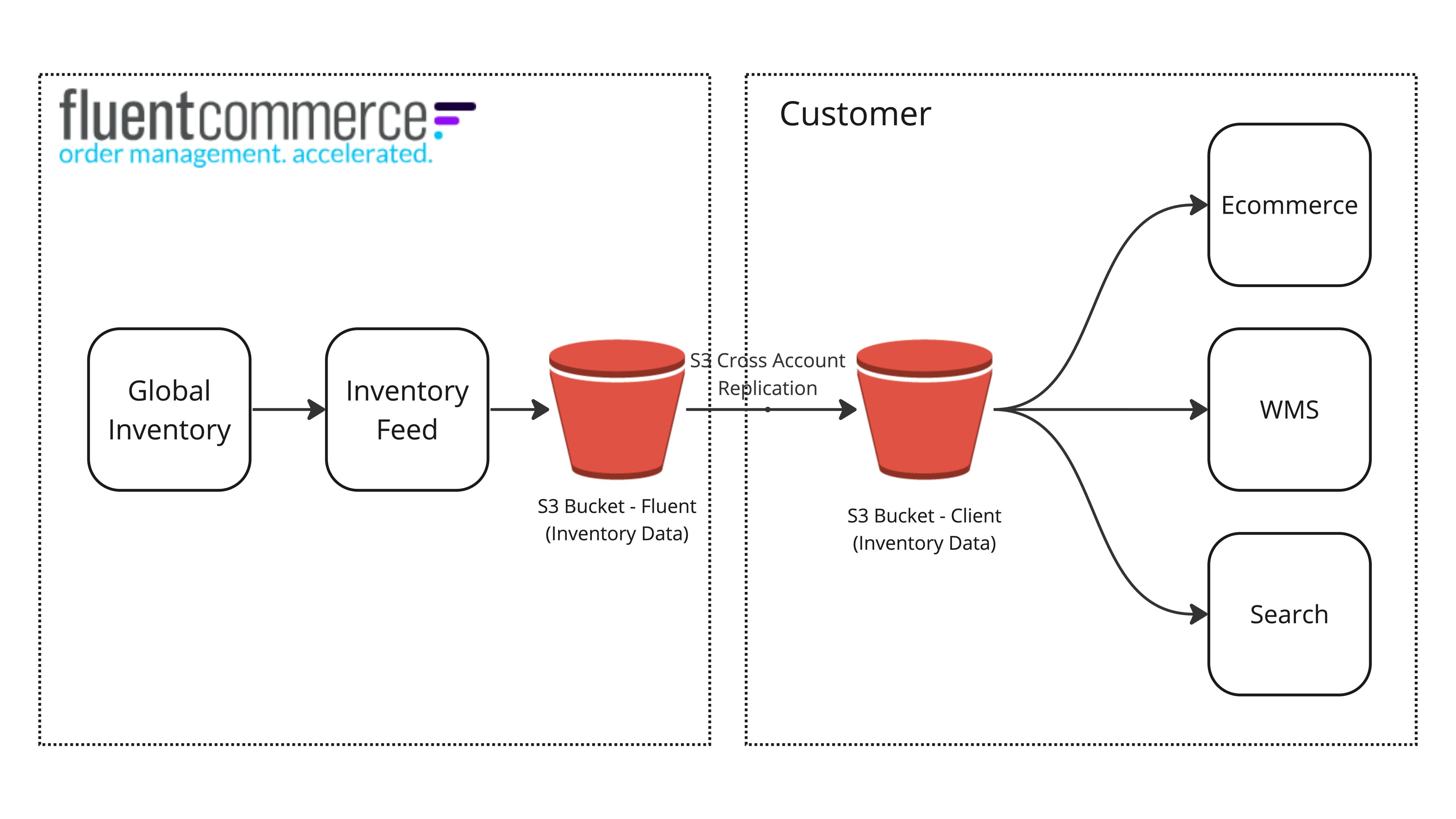
| Field | Description | Type |
| id | Unique ID for the Virtual or Inventory Position | UUID |
| status | current status of the Virtual or Inventory Position | String |
| quantity | quantity value saved for the Virtual Position (only saved in exports of type Virtual_Position) | Integer |
| onhand_quantity | quantity value saved for the Inventory Position (only saved in exports of type Inventory_Position) | Integer |
| group_reference | Location or Network reference for the Virtual Position (only saved in exports of type Virtual_Position) | String |
| location_reference | Location reference for the Inventory Position (only saved in exports of type Inventory_Position) | String |
| virtual_position_type | Type of Virtual Position (only saved in exports of type Virtual_Position) | String |
| inventory_position_type | Type of Inventory Position (only saved in exports of type Inventory_Position) | String |
| created_on | Time the Virtual or Inventory Position was created | DateTime |
| updated_on | Last time the Virtual or Inventory Position was updated | DateTime |
| product_reference | Reference for the Product associated with the Virtual of Inventory Position | String |
| catalogue_id | Unique id for the catalogue of the Virtual or Inventory Position | UUID |
| external_reference | Ref of the Virtual or Inventory Position | String |

Copyright © 2024-2026 Fluent Retail Pty Ltd (trading as Fluent Commerce). Unless otherwise expressly stated in a current written agreement with Fluent Commerce or any of its affiliates or on any single page of the docs.fluentcommerce.com site, use of the materials on this site is strictly limited to viewing by individuals over 18 years old for legitimate commercially appropriate reasons; and any downloading, copying or other actions or uses of any kind or by any means of the materials on this site, including by artificial intelligence tools, is strictly prohibited. All other rights reserved.