How do Inventory Feeds work
Essential knowledge
Author:
Fluent Commerce
Changed on:
22 Aug 2024
Overview
This document will describe how Inventory Feeds work and guide users through understanding any prerequisites to integrate with Inventory Feeds.Key points
- Inventory Feeds will export a view of inventory data from the Fluent platform into a Customer environment
- The schedule of the export is configurable based on the Customer requirements
- The exported data is ready to be synced with any further systems within a Customer ecosystem to provide real time inventory availability
Pre-Requisites
This document assumes you are knowledgeable and aware of the following subjects:- GraphQL API
- Fluent Big Inventory
- Inventory Module
- Specifically Virtual Catalogues and Inventory Catalogues
- Amazon Web Services and AWS Simple Storage Solution
Inventory Feed Components
Inventory Feeds is an inventory availability data export tool. They allow users to create a programmatic export of selected inventory data, ready to be consumed by any inventory-aware system.Inventory Feeds contain two technical components:- Inventory Feed
- Inventory Feed Run
Inventory Feed
The Inventory Feed component is the “parent” data modal of the Inventory Feed. This is where an Inventory Feed is configured and set up. At the Inventory Feed level, you can define information such as:- Export Schedule
- Target destination
- Data filters
Inventory Feed Run
Under an Inventory Feed, there is a one-to-many relationship to Inventory Feed Runs. Each Run is an individual execution that exports a new data file based on the configuration of the parent Inventory Feed.Each Inventory Feed Run contains information such as:- Status of the run (success / failed)
- Total amount of exported inventory items
- Type of run (incremental or full)
Inventory Feed Data Flow
Inventory Feeds are designed to export tailored views of inventory availability into your own ecosystem. Once the data has been exported to your ecosystem, it will be in an easy-to-use format and ready to be shared with any other systems that benefit from inventory availability.High-Level Diagram
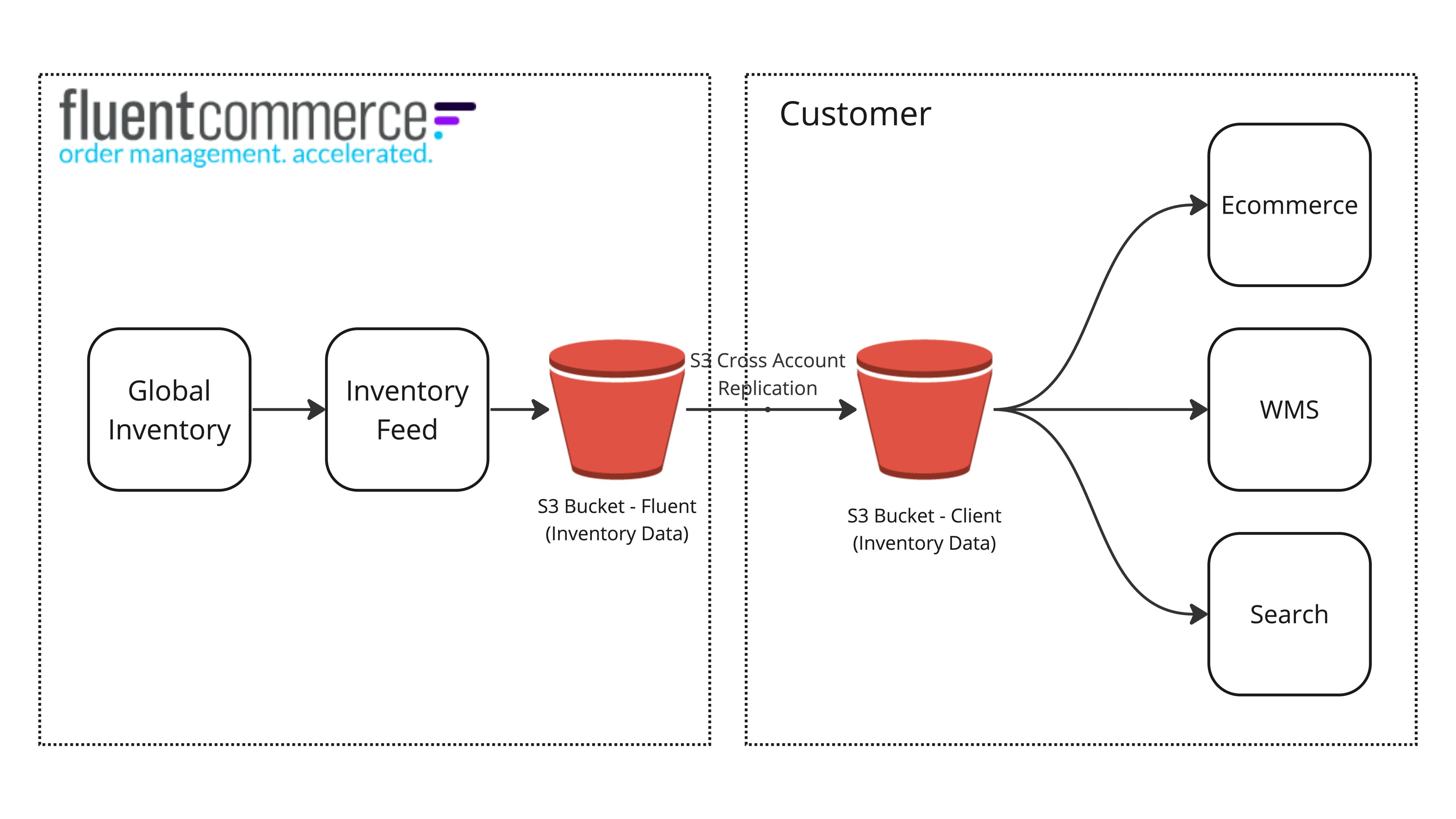
Data Flow
Inventory Feeds are designed to provide data in a format that can be “owned” by the user. Fluent Big Inventory is designed for configurability and extensibility, and this solution enables our customers and partners to best integrate the data from Fluent into a target storage location that can then be integrated into any target system.How it works
The Inventory Feeds service will trigger a run based on the parent configuration, or 5 minutes by default. When a run executes, it will generate an output of the inventory availability from Global Inventory. This generated view of inventory will be saved into an S3 bucket within the Fluent technology stack.When configuring an inventory feed, a customer- or Partner-owned AWS S3 bucket is required as a target destination. Once the target destination bucket is defined, the Inventory Feed service will set up an AWS cross-account replication service. This service will inspect the S3 bucket within the Fluent tech stack. Whenever it identifies any changes or new files added to the Fluent S3 bucket, the cross-account replication service will immediately start to replicate the changes across to the target destination bucket.At this point, the target S3 bucket will have an exact copy of the inventory availability data generated by the Inventory Feed. This data can then be used to provide a view of inventory availability. Additionally, this also provides a historic cache of inventory availability snapshots all the way back to the first initial run of the Inventory Feed.Types of Inventory Feed Runs
Inventory Feed Runs come in two types: FULL and INCREMENTAL. Each Inventory Feed automatically determines the type of run based on its configuration and schedule. Users do not set the run type; the system manages it.Full Feed Run
A Full Feed Run exports all data within the Inventory Feed's configured filters. This type of run establishes a comprehensive starting point for any integration or use of inventory availability data. A Full Feed Run is always triggered the first time an Inventory Feed is activated, ensuring the system starts with a complete set of data. This initial run sets a known foundation, enabling subsequent Incremental Feed Runs to function correctly.Incremental Feed Run
An Incremental Feed Run exports only the data that has changed since the last Inventory Feed Run. The configured filters and the frequency of the Inventory Feed determine the scope of this data. For instance, if an Inventory Feed is set to run every minute, the incremental changes will be relatively small compared to an Inventory Feed that runs once every hour. Incremental Feed Runs keep inventory data up-to-date with minimal data transfer, focusing only on the changes since the previous run.How Inventory Feed Runs Work
When an Inventory Feed is created and activated for the first time, it performs a Full Feed Run. This run extracts and exports all inventory data based on the configured inventory data type and filters, providing a complete dataset. Subsequent Inventory Feed Runs, triggered according to the configured frequency, will be Incremental Feed Runs. These runs will only export the data that has changed since the last run, again limited to the configured inventory data type and filters.File Format
The inventory availability data exported as part of an Inventory Feed will be in a Parquet file format. We have chosen to export in this format because it provides a range of benefits. Some of these benefits are:- Open-source - All customers will be able to use and integrate these file types into their existing architectures
- Schema evolution - Parquet files are designed to evolve. Being column-oriented storage (instead of row-based) and self-describing, Parquet files are designed to evolve, which we expect to happen as we increase the feature set of Inventory Feeds
- Performance - Parquet files are designed for querying directly and, as a result, perform faster than other types of data files such as CSV or JSON
Parquet File Structure
| Field | Description | Type |
| id | Unique ID for the Virtual or Inventory Position | UUID |
| status | current status of the Virtual or Inventory Position | String |
| quantity | quantity value saved for the Virtual Position (only saved in exports of type Virtual_Position) | Integer |
| onhand_quantity | quantity value saved for the Inventory Position (only saved in exports of type Inventory_Position) | Integer |
| group_reference | Location or Network reference for the Virtual Position (only saved in exports of type Virtual_Position) | String |
| location_reference | Location reference for the Inventory Position (only saved in exports of type Inventory_Position) | String |
| virtual_position_type | Type of Virtual Position (only saved in exports of type Virtual_Position) | String |
| inventory_position_type | Type of Inventory Position (only saved in exports of type Inventory_Position) | String |
| created_on | Time the Virtual or Inventory Position was created | DateTime |
| updated_on | Last time the Virtual or Inventory Position was updated | DateTime |
| product_reference | Reference for the Product associated with the Virtual of Inventory Position | String |
| catalogue_id | Unique id for the catalogue of the Virtual or Inventory Position | UUID |
| external_reference | Ref of the Virtual or Inventory Position | String |
Inventory Feed Data Model
