Fluent Connect SDK Architecture
Essential knowledge
Author:
Fluent Commerce
Changed on:
13 Dec 2023
Overview
This article will cover the high-level design and features of the SDK.Key points
- The Connect SDK architecture consists of core, cloud, and additional libraries, enabling the building and extension of connectors.
- Key features include configurations, a secret manager for sensitive information, a scheduler for periodic operations, listeners/subscribers, web services/webhooks, an event log, product availability options, and SDK handlers for custom business logic.
- The message lifecycle follows a specific flow, and there are two integration approaches: Pull and Push. The SDK offers patterns for scheduled operations and receiving external requests, and it includes dead letter queues, metrics, and logs for monitoring and observability.
- Build and deployment use SpringBoot, generating a deployable JAR with an embedded Tomcat.
SDK Architecture
The Connect SDK has many libraries to enable new connectors to be built and extend existing prebuilt connectors. These libraries can be divided into three main sections:- Core: Always required as it will contain minimal functionality for the SDK to function. It brings standard integration features and the native capability to talk to Fluent.
- Cloud: Enables the SDK to be deployed at a specific cloud vendor and utilizes some of its features.
- Other / Additional: Additional features of the SDK.
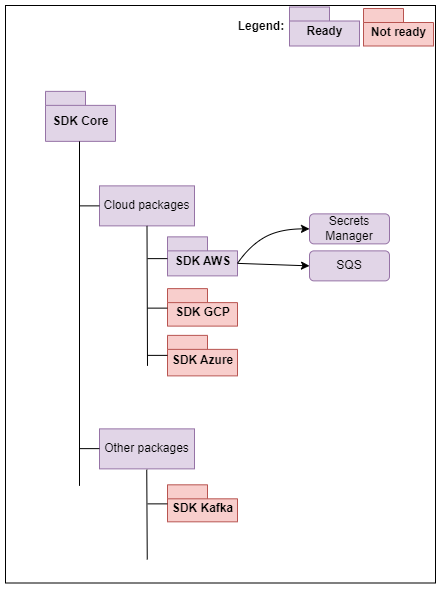 From another perspective, the SDK is usually coupled with a cloud and a vendor/partner-specific library. Although it is possible to combine multiple vendor libraries, such as Commercetools, with a Shipping module like Shippit, it is important to understand service boundaries and whether one module would interfere with the other.
From another perspective, the SDK is usually coupled with a cloud and a vendor/partner-specific library. Although it is possible to combine multiple vendor libraries, such as Commercetools, with a Shipping module like Shippit, it is important to understand service boundaries and whether one module would interfere with the other.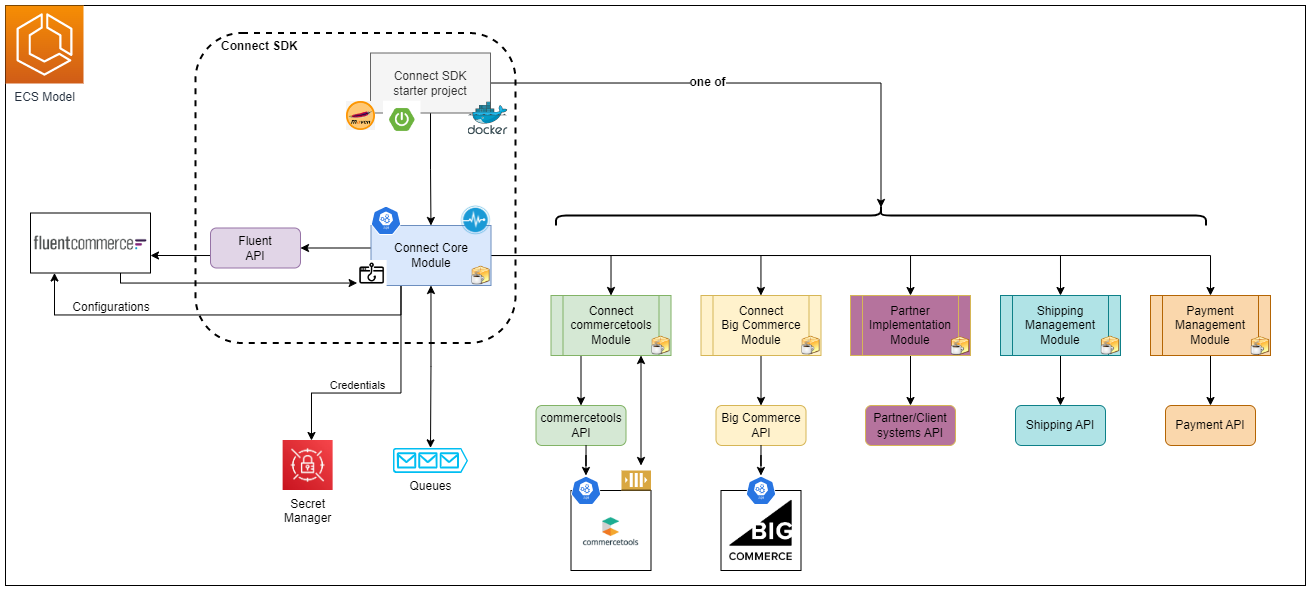 Taking an integration with Commercetools as an example, the diagram below illustrates different possible use cases of how different libraries can be combined to achieve the same level of integration between Fluent and Commercetools.
Taking an integration with Commercetools as an example, the diagram below illustrates different possible use cases of how different libraries can be combined to achieve the same level of integration between Fluent and Commercetools.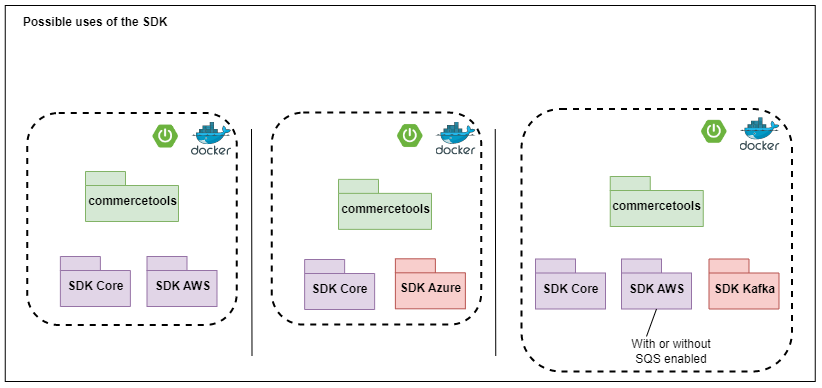
Key SDK Features
The key features described below are covered in more detail in Configure and Customise guides.Configuration
The SDK has two types of configurations: Build time and Runtime.- Build time: These are part of the build artifact and can not change without a new build or deployment.
- Runtime: Users can modify configurations at any given time without a build or deployment.
Secret Manager
Stores' sensitive information, such as credentials, is used by the SDK to connect to external systems. This also specifies what Fluent accounts-retailers are available to the SDK, which essentially locks the SDK to the specified accounts-retailers.Scheduler
The SDK includes a lightweight scheduler approach that executes periodic operations. This is often used when the SDK needs to fetch information from external systems and have them processed. The implementation of the scheduler may change depending on the libraries used, and the first available implementation is through the AWS library. It uses a combination of EventBridge as the actual scheduler, and when the time is right, it requests the SDK to have the operation/job executed.Listener/Subscriber
Listeners are probably the best use of the SDK to receive data to be processed. Often, these listeners will subscribe to a topic or queue and await for messages to be received. Details on how messages can be processed are covered further in this article.As different listeners can connect to various subscription services, their operation may differ, and some features may not be available to all implementations, for example, the message read retries. Some may offer the functionality where the consumer (the SDK) has a set time to acknowledge the message read to be removed from the queue; otherwise, it is made available again for reprocessing. Others may not offer, and retry is either not supported or done via another approach. Another thing to consider is if you need to keep a record of your messages after processing or not.Web Services / Webhooks
Web services are an alternative to the listener approach. The SDK bundles the Spring MVC library, allowing partners to open new endpoints as necessary. It is important to note that the native behavior of the SDK is to process data asynchronously, and the same can be said for these web services. Although it is still possible to create synchronous endpoints, consider if it is required to be a synchronous operation.Event Log
The event log logs any message or operation done by the SDK. This will keep track of messages and operations from when they start processing/executing to when they are completed. By default, the SDK will log these events into log files just like regular application logs, but it is possible to push these events to external systems or a database by adding a new library that brings this ability to the SDK.Product Availability
Product availability is a synchronous operation that returns Fluent Fulfilment Options. The benefits of using it through the SDK are:- Use of an API token as a form of identification. There is no need to perform Oauth authentication and access is granted through the API token and identifying the Fluent account and retailer.
- Enrichment of the response to add and/or pre-process the product availability result before returning it to the caller/client. There can be any number of enrichment steps that consolidate external information along with the product availability data.
- Optional caching of enrichment steps and product availability operation.
SDK Handlers
Handlers play a fundamental role in how the SDK functions. This is where custom business logic is written to perform tasks, whether for a job or a message to be processed.At present, there are three kinds of handlers:- Configuration handler: Can react to configuration (runtime only) changes and perform an action defined by the handler.
- Message handler: Processes messages available to the SDK - it can be either from listeners, web services, or messages generated by jobs.
- Job handler: Perform a scheduled operation.
Message Lifecycle
Any message published to the SDK message queue will follow the below flow.As described on topics above, some listeners may not allow retries.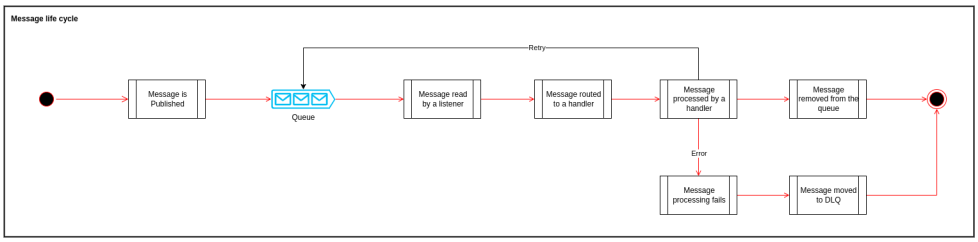
Integration Scenarios
There are typically two integration approaches: Pull or Push. Either the SDK will pull information from other systems, or the SDK will receive information pushed from other systems. When the SDK is on receiving end, listeners or web service can receive the data and have it processed. If the SDK needs to pull the information, a job/periodic operation using the SDK scheduler would be the best fit.Patterns
Scheduled Operations
The diagram below illustrates a hypothetical scenario where the SDK must pull a file from a remote location and process it.The first step of the job is to retrieve a set of records to process and then have it processed, repeating these steps until there are no more. A job may process records sequentially or in parallel. The difference between the two is throughput and error handling.Sequential processing allows the option to abort the job at first failure or skip the record with the issue and resume the processing. In contrast, in parallel processing, the job will not know of any failures when records are processed by messages isolated from the main job thread. It is impossible to perform a wait operation on the job to verify how all messages spawned from a completed job. Any message spawned from a job follows the same lifecycle as any other message in the SDK, and failures are reported as a new entry at the DLQ.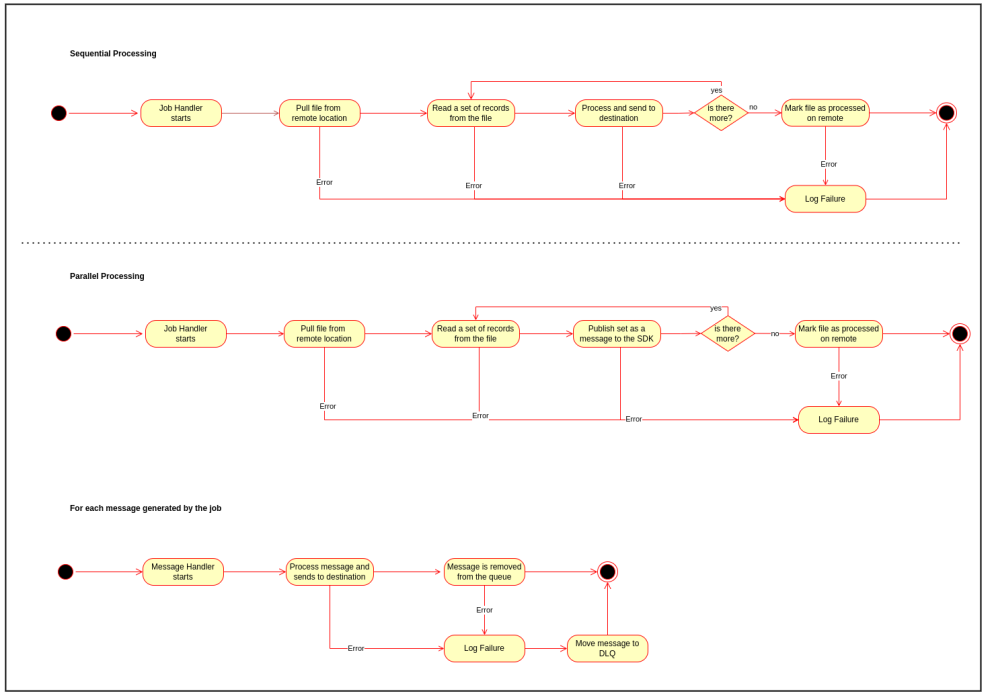 The approach is slightly different when querying external service API to pull data that needs to be processed/synchronized, as shown below.Avoid pulling full extracts from external systems. Use the SDK date tracking feature that assists jobs in pulling only modified data from the last time the job was executed.
The approach is slightly different when querying external service API to pull data that needs to be processed/synchronized, as shown below.Avoid pulling full extracts from external systems. Use the SDK date tracking feature that assists jobs in pulling only modified data from the last time the job was executed.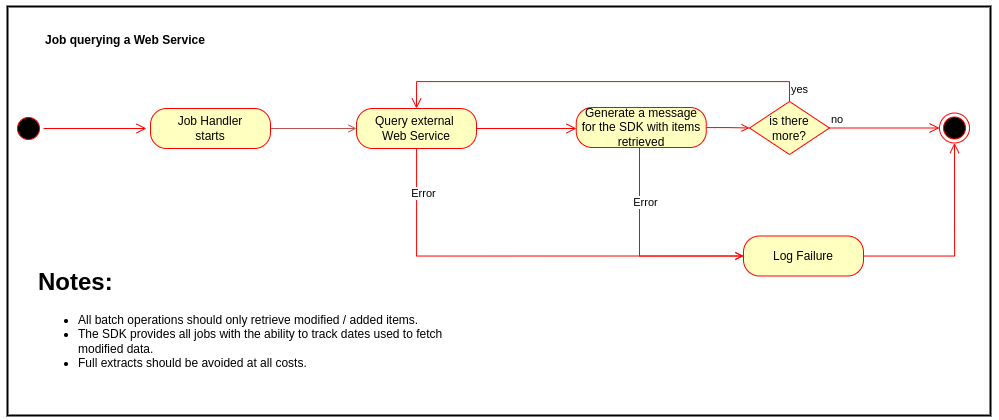
Receiving External Requests
When the connect SDK is on the receiving end, there are 3 options to receive external inputs as described below. It’s important to note that the first option is the least favorable in terms of throughput, but it is still an option when a synchronous operation is required.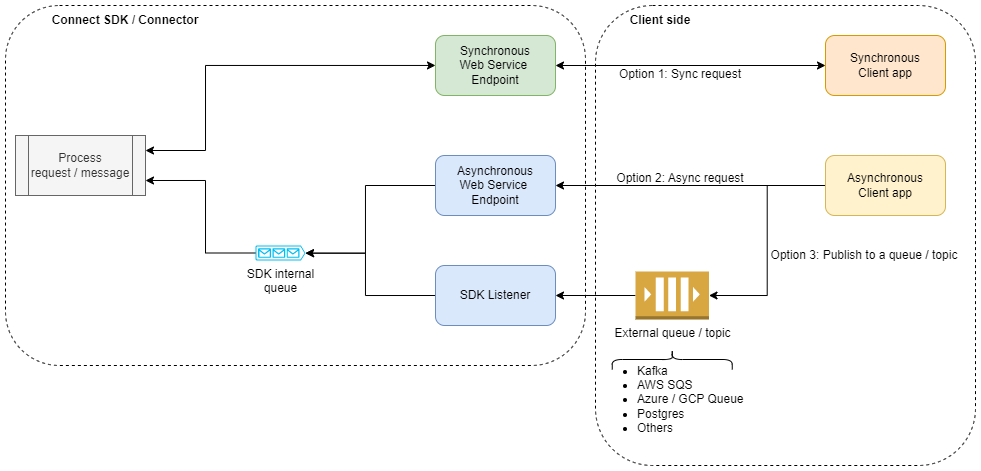
Working With Messages
A message handler should ideally perform a particular task given a message. In cases where the same message needs to be sent to different systems or perhaps different operations are performed against the same message, it is best to split the processing by either splitting the message into new messages routed to different message handlers or forwarding the message to the next handler to process creating chained and sequential processing.- Message Splitting

- Message Forwarding
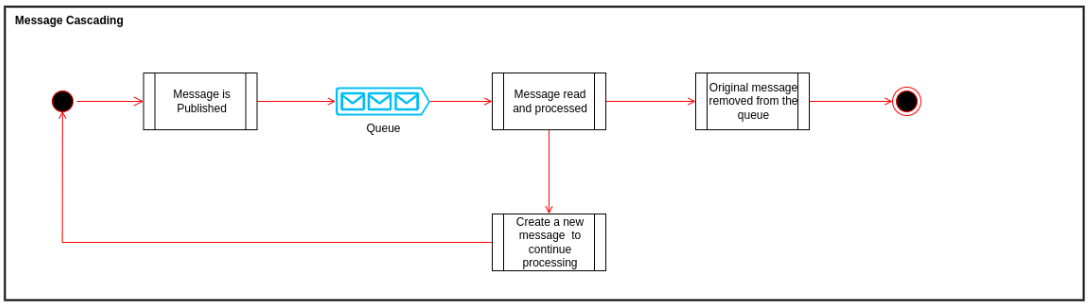
Remarks and Limitations
- SDK does not guarantee that messages are processed in the order they are generated/received.
- Messages may be reprocessed multiple times, mainly when they perform multiple tasks and fail halfway.
- Note that the decision of whether a message should be reprocessed is always under the control of the message handler.
- SDK does not support wait or join operations when processing messages - the SDK does not maintain any state.
Product Availability Structure
The SDK provides an HTTP endpoint`/api/v1/fluent-connect/fulfilment-option` with a default implementation to return product availability options, and its contract can be found at `/api/docs`.When a request is made to the SDK, the token is first validated to ensure it exists and is valid/not expired. Once that's done, the Fluent account and retailer are identified, and the payload is translated into a graphQL query. The SDK provides a standard translation, but partners can modify this if necessary. With the GraphQL query built, the SDK requests Fluent to obtain the fulfillment options. The result goes through a chain of transformation/enrichment steps that partners can add custom behavior to either enrich or modify the initial response from Fluent. The SDK will also provide a caching ability so frequently used enrichment steps that don’t change often can be cached and, in turn, avoid making unnecessary external calls.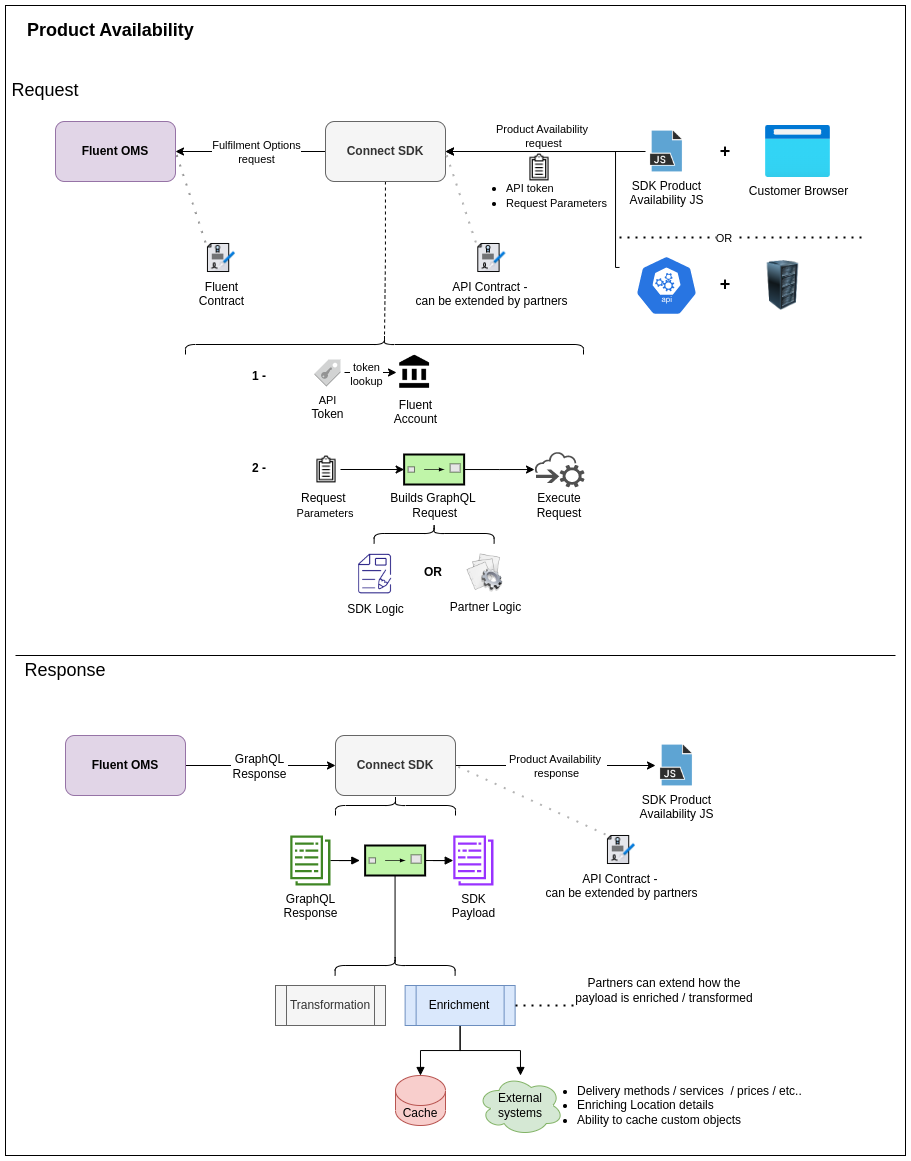 Additional details can be found in configure and customize sections.
Additional details can be found in configure and customize sections.Connector Example
The example below covers both listener, scheduled operations, and Fluent webhooks. The bottom half of the diagram is where a connector can receive messages from external systems, and the SDK routes it to the appropriate message handlers.The upper half covers both Fluent webhook and scheduled operations. In the example, there are two scheduled operations: one to fetch products that have been updated and the other to fetch inventory updates. Both jobs fetch data from external systems (one Fluent and the other an external system), generate messages for retrieved items, and publish them to the SDK events queue. This will use the same events queue and message handlers as when receiving messages from listeners.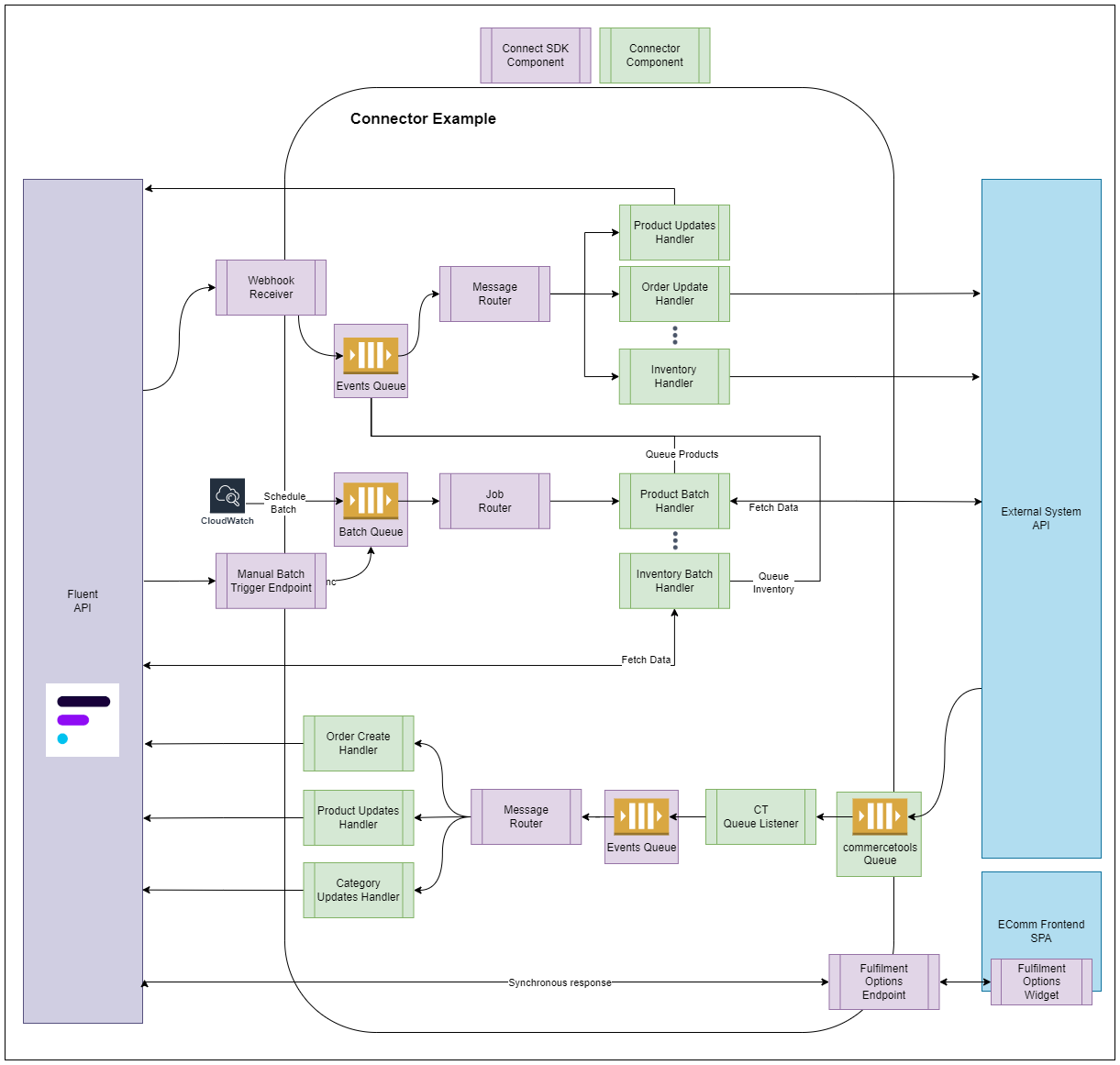
Build / Deployment
The SDK uses SpringBoot, which generates a jar when built/packaged. The application runs on an embedded Tomcat included in the jar. A docker file is also bundled with the project that can be used to build a docker image, which can be deployed to your preferred location.The SDK starting project includes a script named`build.sh` that can build the project and generate a docker image called `fluent_connector`.Monitoring / Observability
Dead Letter Queues
All asynchronous processing is done through the queues (listeners), and any failure to process a message or job will cause the SDK to move that particular entry to the dead letter queue (DLQ).Monitoring of the DLQ is crucial to detect failures within the SDK.The recovery process of a message moved to the DLQ involves determining the date the message was moved and, with this date, looking at the event log to understand why it failed and the sequence of events that precedes the failure. Messages that can be reprocessed can be manually moved back to the queue they originated from, and the SDK will reprocess them.Metrics
OpenTelemetry is included with the SDK, and specific libraries can be included to push them to the desired system to monitor them. As in the example below, the library pushes the metrics to CloudWatch.1<dependency>
2 <groupId>io.micrometer</groupId>
3 <artifactId>micrometer-registry-cloudwatch</artifactId>
4</dependency>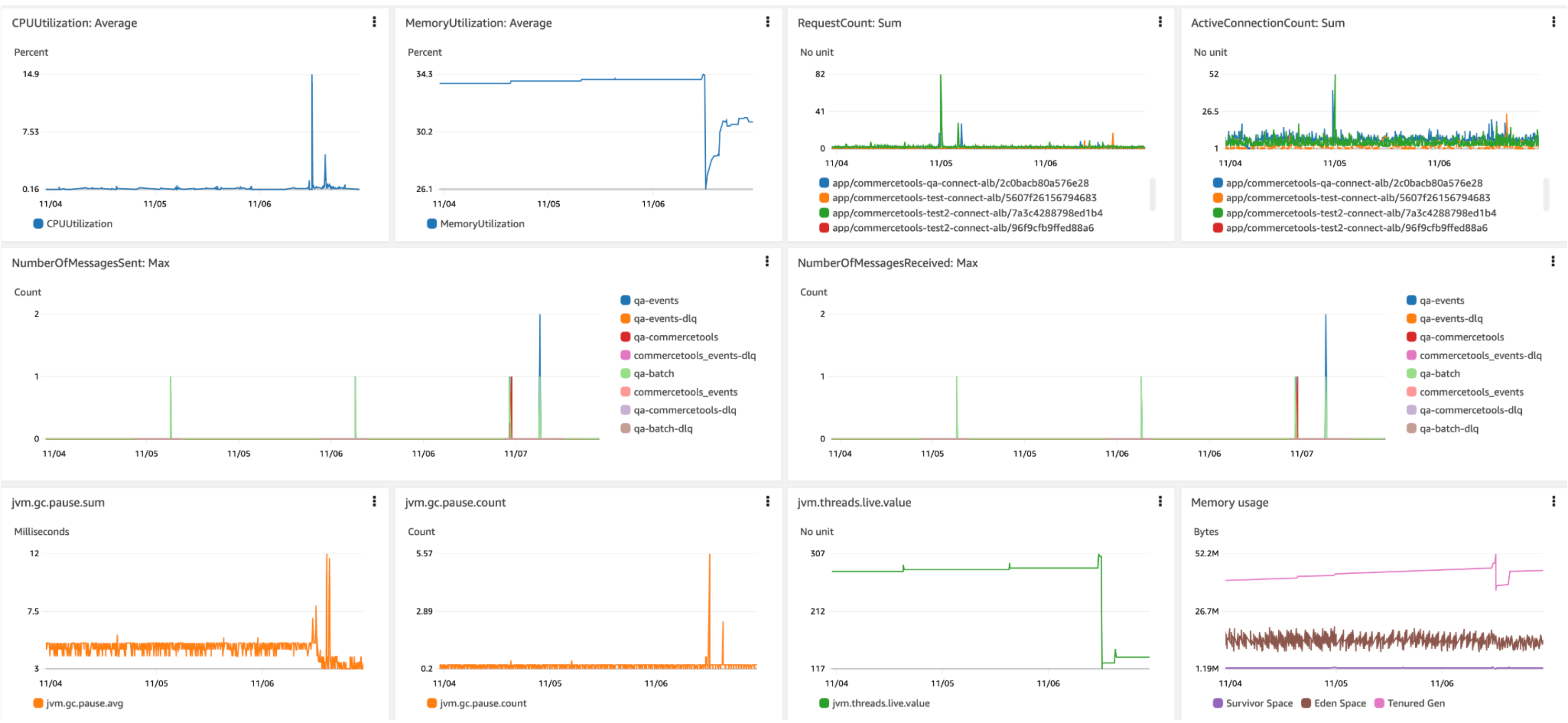
Logs
SDK uses SLF4J with Logback for logging, including log rotation and auto cleanup by default. The settings can be found at`logback-spring.xml`.
Application Logs
SDK standard application logs are logged at`connector.log`.Event Logs
Event logs, when using the default the implementation will push logs to`event_log.log`. This file only contains event logs registered with the SDK.