Inventory File Loader
How-to Guide
Author:
Fluent Commerce
Changed on:
9 Oct 2023
Key Points
- The SDK allows to import data into Fluent OMS via batch jobs.
- The data can be stored in an Amazon S3 bucket and imported into Fluent OMS via API.
- The inventory job handler requires various settings that need to be defined in the account’s settings list ( location-pattern, archive-folder... )
Steps
 Inventory File Loader
Inventory File Loader
Overview
In this sample project, we will go through some basic features of the SDK by creating a batch job that can read resources (from a file path, S3 …) and then load to Fluent System.These are the topics covered by this guide:- Spring Batch overview
- Create a new Batch Job Handler
Prerequisites
- localstack container is running
- You have access to a Fluent account
`localstack-setup.sh` bundled with the project that can be used to set up localstack. The script requires some parameters to be configured before it can be executed.It is best to do the following:First, run this command to open a session with the localstack containerThen use the commands below to create the secrets, but ensure to update the variables: $ACCOUNT, $RETAILER, $USERNAME, $PASSWORD and $REGION. Regions values are: sydney, dublin, singapore or north_america.Use ctrl + D to exit the localstack session.
Spring Batch overview
Spring Batch is a Java framework for writing and executing multi-step, chunk-oriented batch jobs. It provides reusable functions essential in processing large volumes of records, including logging/tracing, transaction management, job processing statistics, job restart, skip, and resource management.Architecturally, Spring Batch is divided into three main components:- Job: Represents the batch job and contains one or more steps.
- Step: Represents an individual unit of work within a job, typically defined as a single chunk-oriented task, such as reading data from a database, transforming the data, and writing the results to a file.
- Processing: These components define the reading, processing, and writing of individual data items within a step
- Chunk-oriented processing: It is a step-based approach where data is read, processed, and written in small chunks
- Tasklet-based processing: It is a single-step approach where a single task is executed. Tasklets are typically used for operations such as cleaning up resources or initializing a database. Tasklet-based processing is best suited for scenarios where a single, well-defined task needs to be executed and is not necessarily concerned with large amounts of data.

Create a new Batch Job Handler
Scenario:- The e-commerce system generates inventory files in CSV format on an hourly basis, which are stored in the Amazon S3 bucket, "sample-bucket". The object keys for these files are in the format of "samples/inventory-YYYYMMDDHHMMSS.csv".
- A connector has been implemented to facilitate data transfer from Amazon S3 to Fluent by Batch API. This process consists of the following steps:
- Downloading the CSV files from Amazon S3 using a reader component.
- Parsing the data contained within the CSV files
- Loading/importing the parsed data to Fluent by Batch API using a writer component.
- Moving the processed files from the original location to an archive location is accomplished through the use of an ArchiveTasklet.
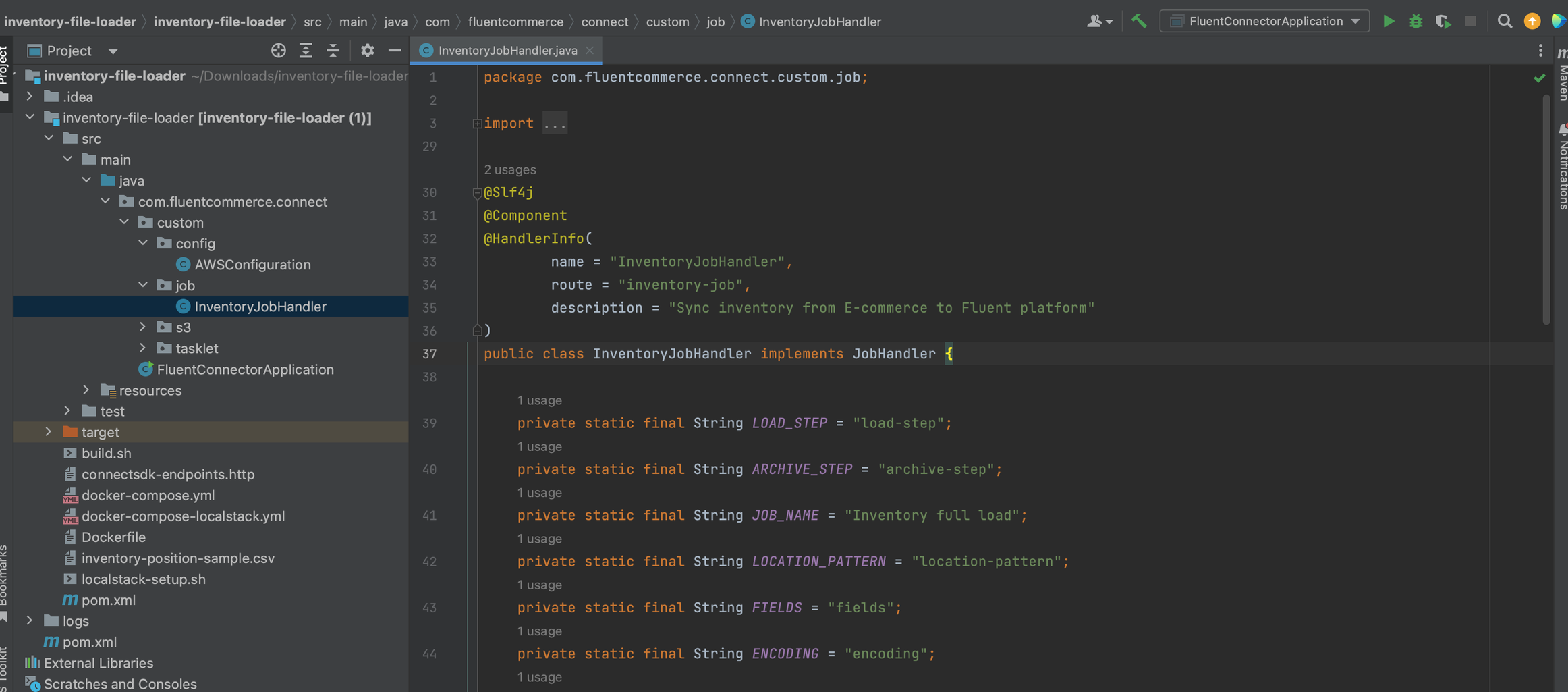 The code uses the
The code uses the `@HandlerInfo` and `@HandlerProp` annotations to specify the properties of the batch job such as the name, route, description, and properties required for the job to run. The job requires the following properties:Define a job setting on Fluent OMS- Key: fc.connect.inventory-file-loader.batch.inventory-job
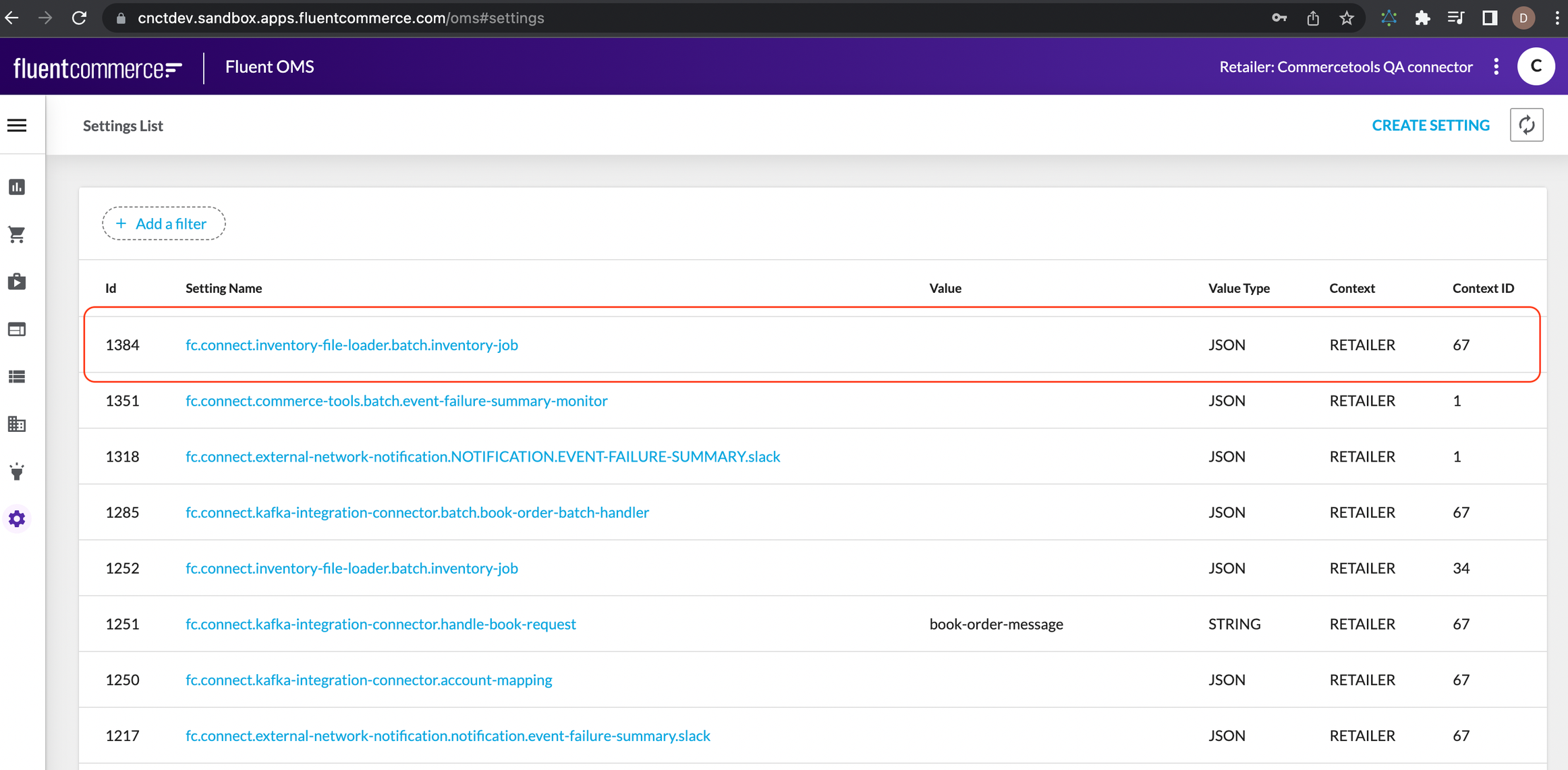
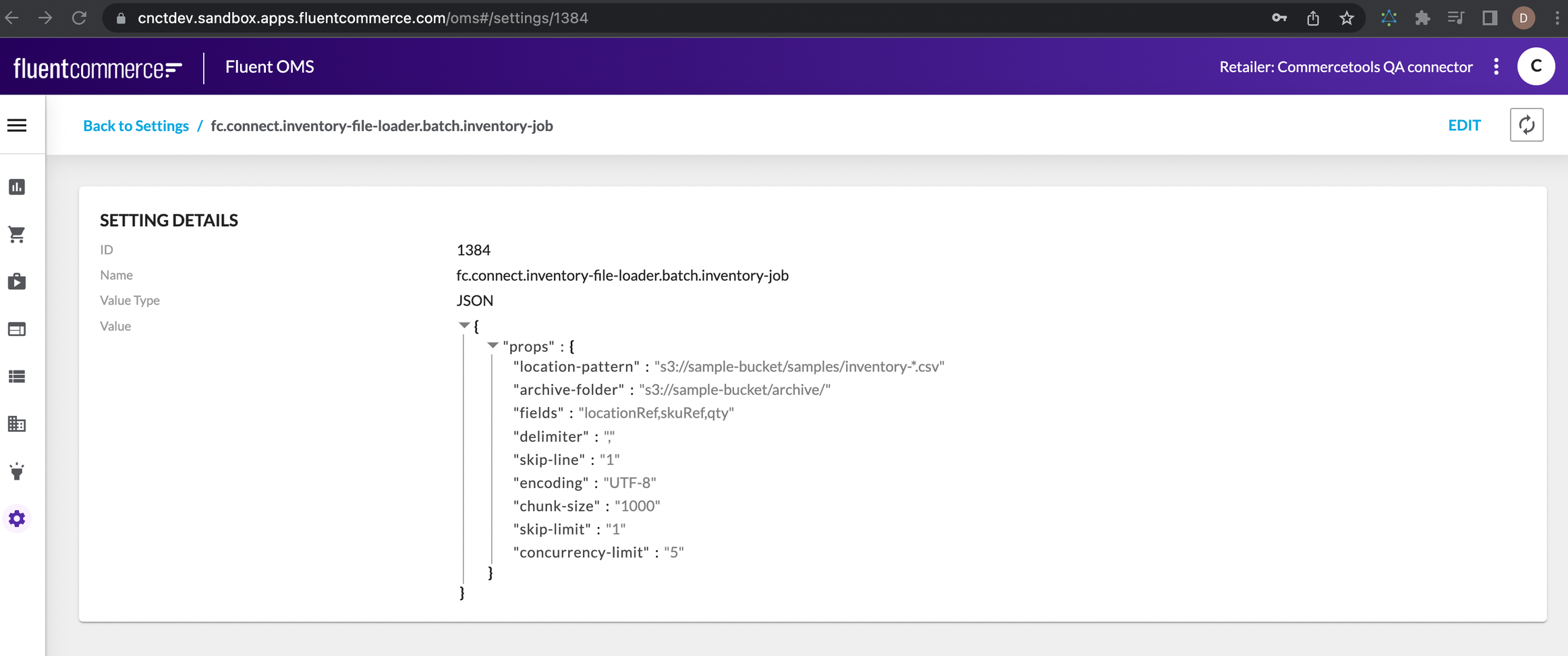
- Value:
- location-pattern: The location pattern of the CSV file in S3 (e.g. "s3://sample-bucket/samples/inventory*.csv").
- archive-folder: The archive folder in S3 where the processed CSV files will be moved to (e.g. "s3://sample-bucket/archive/").
- fields: The fields in the CSV file that should be processed (e.g. "locationRef,skuRef,qty").
- delimiter: The delimiter used in the CSV file (e.g. ",").
- skip-line: The number of lines to skip at the beginning of the CSV file (e.g. 1).
- encoding: The encoding used in the CSV file (e.g. "UTF-8").
- chunk-size: The chunk size for processing the data in the CSV file (e.g. 5000). If your
`chunk-size`is set to`100`, then the reader will read 100 records at a time, and the writer will write those 100 records in a single transaction. If the next 100 records are read, they will also be written in a single transaction. This process continues until all records have been processed. If you do not specify a`chunk-size`, Spring Batch will use the default value of`10`, meaning that 10 records will be processed in a single transaction. It's important to note that specifying a`chunk-size`that is too large can cause performance issues and affect the overall efficiency of your batch process. On the other hand, specifying a chunk-size that is too small can cause too many transactions to occur, leading to increased overhead and decreased performance. The optimal`chunk-size`depends on the specifics of your application and should be chosen carefully. - skip-limit: The number of times to skip an error during processing (e.g. 500).
- concurrency-limit: The concurrency limit for processing the data in the CSV file (e.g. 5).
 Resolve resources:This is an example of S3 resources resolver. The order of resources in a
Resolve resources:This is an example of S3 resources resolver. The order of resources in a `Reader` can be defined by the order in which the resources are specified in the `resources` propertyIn this example, the resources are sorted using the
`Arrays.sort` method and a custom `Comparator` that defines the order of resources. In this case, the order of resources is determined based on the file name of each resource. The reader will read each resource in the order it appears in the list, processing the records in each resource before moving on to the next one.Partner can resolve any kind of resources that provided by Spring or custom one (Refer to 6. Resources)
Example:Resource[] resources = resourcePatternResolver.getResources("file:/foo/bar/**);Resource[] resources = resourcePatternResolver.getResources("s3:/foo/bar/**);Resource[] resources = resourcePatternResolver.getResources("http://foo.com/bar/**);Note: As Fluent's Batch API functions asynchronously, it cannot guarantee the sequence of resource processing, whereby resource 2 may execute before resource 1 is persisted. To ensure data integrity, it is recommended to ensure resource data is unique or to consider processing only one resource at a time.Define the Reader:
`CsvItemReader` was built on top of `FlatFileItemReader`Define the Writer:`FluentInventoryItemWriter` was implementation of `ItemWriter`Define the process step:Define a Tasklet to move/archive files to another location on Amazon S3:Define the archiveTasklet:Define the archiveStep:Launch the Batch Job:Parameters:- id: id of batch job. By default, Spring Batch provide ability to indicate a job instance with the same parameters has already been executed or completed.
- name: name of batch job
- steps: accept a variable number of steps and execute steps follow the order. Examples:
- batchJobBuilder.launchJob(id, name, prepareStep, loadStep, archiveStep): execute 3 steps by the order: prepareStep > loadStep > archiveStep
- batchJobBuilder.launchJob(id, name, loadStep, archiveStep): execute 2 steps by the order: loadStep > archiveStep
- batchJobBuilder.launchJob(id, name, loadStep): execute only 1 step
- batchJobBuilder.launchJob(id, name, prepareStep, loadStep, archiveStep): execute 3 steps by the order: prepareStep > loadStep > archiveStep
Trigger Job
